This dictionary aims to briefly explain the most important terms from Andrew.Ng’s deeplearning.ai. It contains short explainations of the terms, accompanied by links to follow-up posts, images, and original papers. The post aims to be equally useful for Deep Learning beginners and practitioners.
Activation Function
Used to create a non-linear transformation of the input. The input are multiplied by weights and added to a bias term. Popular Activation functions include ReLU, tanh, or sigmoid.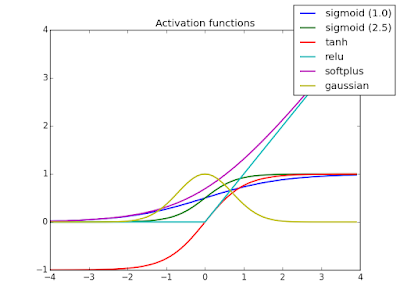
Adam Optimization
Can be used instead of stochastic gradien descent optimization methods to iteratively adjust network weights. Adam is computationally efficient, works well with large data sets, and requires little hyperparameter tuning, according to the inventors. Adam uses an adaptive learning rate a, instead of a predefined and fixed learning rate. Adam is currently the default optimization algorithm in deep learning models.
Adaptive Gradient Algorithm
AdaGrad is a gradient descent optimization algorithm that features an adjustable leaning rate for every parameter. AdaGrad adjusts the parameters on frequently updated parameters in smaller steps than for less frequently parameters. It thus fares well on very sparse data sets, e.g. for adapting word embeddings in Natural Language Process tasks.
Average Pooling
Averages the results of a convolutional operation. It is often used to shrink the size of an ipput. Average pooling was primarily used in older Convolutional Neural Networks architectures, while recent architectures favor maximum pooling.
AlexNet
A popular CNN architecture with eight layers. Itis a more extensive network architecture than LeNet and takes longer to train. AlexNet won the 2012 ImageNet image classification challenge.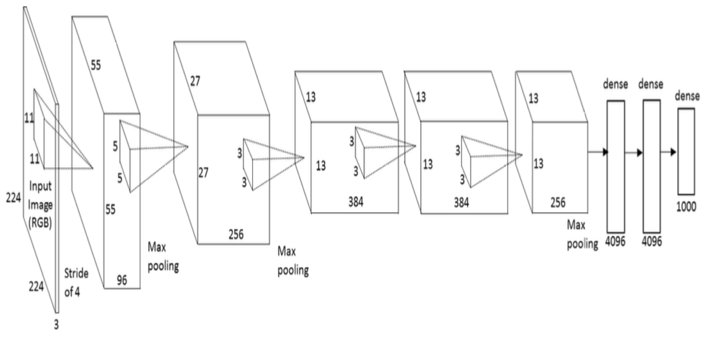
Backpropagation
The genreal framework used to adjust network weights to minimize the loss function of a neural network. The algorithm travels backward throught the network and adjusts the weights throught a form of gradient descent of each activation function.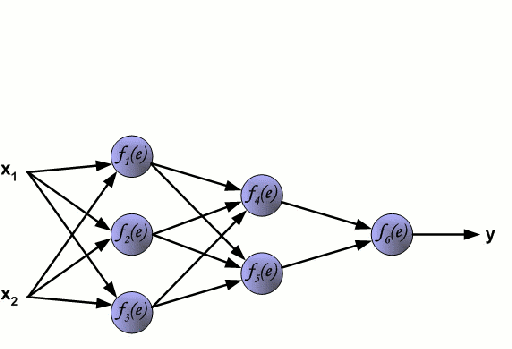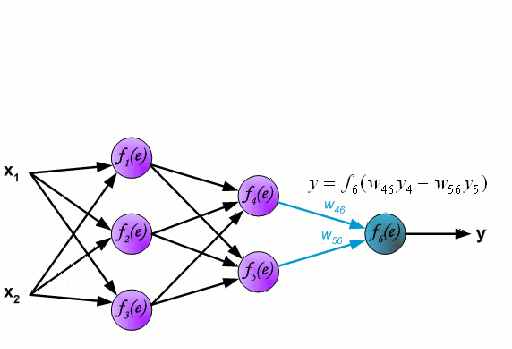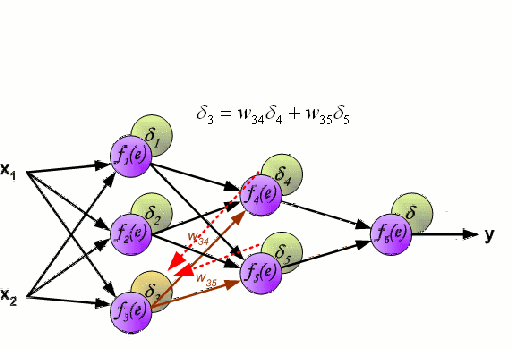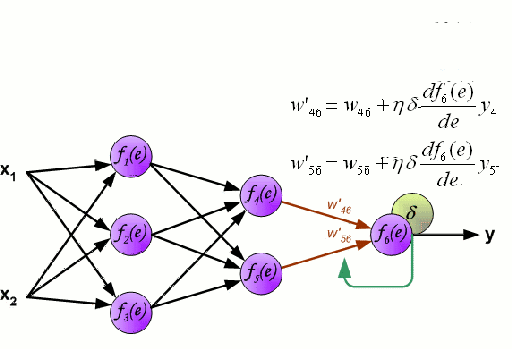
Bias
Occurs when the model does not achieve a high accuracy on the training set. It is also called underfitting. When a model has a high bias, it will generally not yield high accuracy on the test set.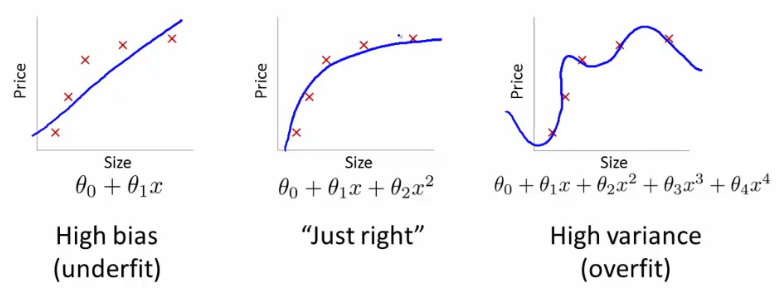
Cost Function
Defines the difference between the calculated output and what it should be. Coust functions are one of the key ingredients of learning in deep neural networds, as they form the basis for parameter updates. The network compares the outcoume of its forward propagation with the ground truth and adjusts the network weights accordingly to minimize the cost function.
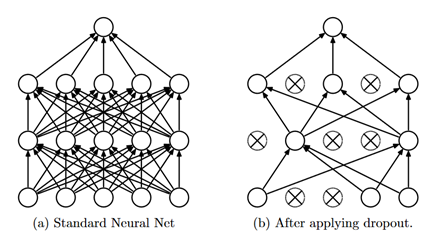
Deopout
A regularization technique which randomly eliminates nodes and its connections in deep neural networks. Dropout reduces overfitting and enables faster training of deep neural networks. Each parameter update cycle, different nodes are dropped during training. This forces neighboring nodes to acoid relying on each other too much and figuring out the correct representation themselves. It also improves the performance of certain classification tasks.